
 KI stößt dort an ihre Grenzen, wo das Trainieren intelligenter Systeme und Algorithmen mit menschlichem Aufwand verbunden ist. Expertensysteme sind dafür das beste Beispiel: Im Zeitalter von Big Data und IoT liefern Sensoren so große Datenmengen, dass kein Mensch mehr mit dem Füttern der Rechnersysteme nachkommen kann. Die Maschinen, das war schon iin den Urtagen der KI in den 50er Jahren klar, werden lernen müssen, selber zu lernen.
KI stößt dort an ihre Grenzen, wo das Trainieren intelligenter Systeme und Algorithmen mit menschlichem Aufwand verbunden ist. Expertensysteme sind dafür das beste Beispiel: Im Zeitalter von Big Data und IoT liefern Sensoren so große Datenmengen, dass kein Mensch mehr mit dem Füttern der Rechnersysteme nachkommen kann. Die Maschinen, das war schon iin den Urtagen der KI in den 50er Jahren klar, werden lernen müssen, selber zu lernen.
AI-Pionier Marvin Minsky schuf bereits 1951 die erste lernende Maschine, die er SNARC nannte (die Abkürzung von Stochastic neural analog reinforcement calculator), ein neuronaler Netzcomputer, der das Verhalten einer Maus in einem Labyrinth simulieren sollte. Die virtuelle Maus war in der Lage, ohne fremde Hilfe einen Weg aus dem Irrgarten zu finden, indem es immer neue Versuche unternahm, sich aber das Ergebnis der früheren Versuche merken konnte. Das ist auch die Methode, mit der Kleinkinder lernen und ihre Umgebung erforschen: Gebranntes Kind scheut bekanntlich das Feuer! Es wird quasi künstliches Wissen aus Erfahrungen generiert. Die aus den Daten gewonnenen Erkenntnisse lassen sich verallgemeinern und für neue Problemlösungen oder für die Analyse von bisher unbekannten Daten verwenden.
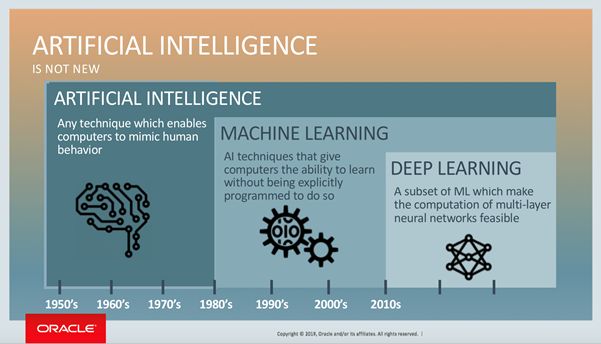
Maschinenlernen (Machine Learning) beschreibt also Algorithmen, die sich in Abhängigkeit von den Eingangsdaten selbst anpassen können. Auf diese Art können Muster und Gesetzmäßigkeiten in Datenbeständen erkannt werden, um darauf basierend Vorhersagen zu treffen. Typische Anwendungsgebiete für Machine Learning sind etwa Spamfilter, Prognosesysteme (z. B. Wetter) sowie Betrugserkennung.
Deep Learning ist der Teilbereich des Machine Learning, dem die KI-Forschung gerade die allerhöchste Aufmerksamkeit widmet. Sie nutzt neuronale Netze, die sich an der Funktionsweise des menschlichen Gehirns ausrichten, um aus riesigen Datenmengen belastbare Prognosen und Entscheidungen abzuleiten, ohne dass dazu menschliches Eingreifen nötig ist. Deep Learning setzt umfangreiches Training voraus. Dazu wird das System mit bereits vorhandenem Wissen gefüttert, beispielsweise Bilddatenbanken, die es anschließend mit unbekannten Daten vergleicht und analysiert. Der Vorteil gegenüber den alten Expertensystemen der 80er Jahre liegt in dem wesentlich geringeren Trainingsaufwand: Der Mensch muss dem System nur eindeutig sagen, ob das zu identifizierende Objekt auf dem Bild zu sehen ist oder nicht (zum Beispiel eine Ampel oder ein Fußgänger). Das Deep Learning-Programm benützt diese Information, um die typischen Merkmale einer Ampel oder eines Fußgängers zu „lernen“ und daraus ein Vorhersagemodell zu entwickeln. Dazu arbeitet sich das Programm immer tiefer in die Zwischenschichten des neuronalen Netzes hinein – daher der Begriff „Deep Learning“. So kann es sein, dass die Knoten oder Einheiten der ersten Zwischenschicht lediglich die Helligkeit der Bildpixel registrieren. Die nächste Schicht könnte erkennen, dass bestimmte Pixel Linien bilden. Die dritte Ebene könnte zwischen horizontalen und vertikalen Linien unterscheiden, und so weiter, bis das System am Ende Arme, Beine und Gesichter erkennen kann und damit in der Lage ist, die abgebildete Person als „Fußgänger“ zu klassifizieren.
Da dieses Training weitgehend automatisch abläuft, hält sich der menschliche Aufwand in Grenzen. Allerdings setzten solche Lernzyklen eine erhebliche Rechenleistung voraus. Das ist auch der Grund, warum solche Systeme erst heute wirklich funktionieren, denn die Rechenpower der Hochleistungscomputer heutiger Bauart sind Dank Moore’s Law um mehrere Tausenderpotenzen schneller als noch vor ein paar Jahren. Die Geschwindigkeit eines Supercomputers wird in seiner Fähigkeit gemessen, so genannte Gleitkommaoperationen abzuarbeiten – englisch floating point operations, oder FLOPS. Operationen sind dabei mathematische Funktionen wie das Addieren und Multiplizieren von Zahlen.
Computerlabore auf der ganzen Welt befinden sich in einem erbitterten Wettlauf darum, wer den schnellsten Computer der Welt bauen kann. Im Juni 2019 ging der Titel wohl an das Oak Ridge National Laboratory (ORNL) im US-Bundesstaat Tennessee, deren Supercompter Summit in der Lage ist, fast 150 petaFLOPS pro Sekunde zu verarbeiten. Ein petaFLOP sind eine Billion FLOPS, also eine Eins gefolgt von fünfzehn Nullen (1015). Computerwissenschaftler und Herstellerfirmen arbeiten jedoch fieberhaft an immer neuen Generationen von speziellen KI-Chips sowie am Fernziel eines so genannten Quantum Computers, der die geheimnisvollen Eigenschaften der Quantenphysik nutzbar machen soll und mindestens tausendmal schneller sein dürfte als der schnellste Supercomputer heutiger Bauart. Aber das sind wohl noch ferne Zukunftsträume.
Um allerdings Deep Learning in der Praxis umsetzen zu können, muss die Wissenschaft erst noch das Problem des Austauschs der gewonnen Erkenntnis unter verschiedenen Systemen in den Griff bekommen. Wenn jedes selbstfahrende Auto selbst lernen muss, wie ein Fußgänger aussieht, dauert es viel zu lang. Neuronale Netzwerke sollten in der Lage sein, auf die Ergebnisse des Deep Learning in anderen Systemen zuzugreifen. Die Khronos Group ist ein 2000 gegründetes Industriekonsortium, das sich für die Erstellung und Verwaltung von offenen Standards einsetzt. 2018 hat sie mit dem Neural Network Exchange Format (NNEF) ein Austauschformat für trainierte künstliche neuronale Netze vorgestellt. Entwickler und Datenwissenschaftler sollen damit KIs im System ihrer Wahl trainieren und an jedes anderes neuronale Netzwerk übertragen können – so wie man heute Word- oder Excel-Dateien zwischen beliebigen Computern austauschen kann.
Deep Learning hat seine Stärken in Anwendungen, bei denen es darum geht, große Datenmengen nach Mustern und Modellen zu durchsuchen, also insbesondere in der Gesichts-, Objekt- oder Spracherkennung. Spracherkennungssysteme können beispielsweise ihren Wortschatz selbstständig mit neuen Wörtern oder Redewendungen erweitern. Das beste Beispiel für Deep Learning in der täglichen Praxis sind intelligente Sprachassistenten wie Siri von Apple oder Cortana von Microsoft. Deep Learning kann auch beim Übersetzen von gesprochenen Texten helfen. Weitere Einsatzgebiete sind zum Beispiel Computerspiele, autonome Fahrzeuge, Vorhersagen von Qualitätsproblemen in der Produktion (cognitive manufacturing) oder von Maschinenausfällen (predictive maintenance) oder Prognosen über Kundenverhalten auf Basis von Daten eines CRM-Systems (predictive marketing).


 Lots of videos on my YouTube Channel
Lots of videos on my YouTube Channel
 Meine Smartphonekamera macht sich manchmal beim Knipsen selbständig, und oft kommen dabei wirklich gute Bilder heraus, ohne dass ich etwas dafür kann.
Meine Smartphonekamera macht sich manchmal beim Knipsen selbständig, und oft kommen dabei wirklich gute Bilder heraus, ohne dass ich etwas dafür kann.

 Die zweite überarbeitete und erweitere Auflage ist jetzt hier erhältlich."
Die zweite überarbeitete und erweitere Auflage ist jetzt hier erhältlich."
{kind=link}
Eine Antwort auf Was ist Deep Learning wirklich – und wie neu ist es?